Recueillir des données sur le Web
Vous avez tout essayé, et vous n’êtes toujours pas parvenu à mettre la main sur les données que vous voulez. Vous avez trouvé les données sur le web, mais hélas – aucune option de téléchargement n’est disponible et le copier-coller montre ses limites. N’ayez crainte, il y a toujours un moyen d’extraire les données. Vous pouvez par exemple tenter les actions suivantes.
-
Obtenir les données par l’intermédiaire d’une API web, telles que les interfaces fournies par les bases de données en ligne et de nombreuses applications web modernes (comme Twitter, Facebook et bien d’autres). C’est un moyen fantastique d’accéder à des données gouvernementales ou commerciales et d’extraire des données depuis les réseaux sociaux.
-
Extraire les données de fichiers PDF. C’est très difficile, car le PDF est un langage conçu pour les imprimantes, qui conserve peu d’informations sur la structure des données. L’extraction de données de fichiers PDF dépasse le cadre de ce livre, mais il existe des outils et des tutoriels pour vous y aider.
-
Le screen-scraping (capture de données d’écran) permet d’extraire du contenu structuré à partir d’une page web normale à l’aide d’un outil de scraping ou en écrivant un petit bout de code. Cette méthode est très puissante et peut être utilisée dans de nombreux cas, mais elle requiert une certaine compréhension du fonctionnement du web.
En plus de ces excellentes options techniques, n’oublions pas les options simples : parfois, cela vaut la peine de passer un peu de temps à chercher un fichier contenant des données déjà exploitables ou d’appeler l’institution qui détient les données que vous voulez. Dans ce chapitre, nous allons étudier un exemple très simple de scraping de données à partir d’une page web HTML.
Que sont des données lisibles par machine ?
L’objectif de la plupart de ces méthodes consiste à obtenir des données « lisibles par machine ». Des données lisibles par machine sont créées pour être traitées par un ordinateur, au lieu d’être présentées pour un utilisateur humain. La structure des données est liée aux informations contenues, pas à la façon dont elles seront affichées au final. Parmi les formats facilement lisibles par machine, il y a le CSV, le XLM, le JSON et les fichiers Excel, alors que des formats comme les documents Word, les pages HTML et les fichiers PDF s’intéressent plus à la mise en page visuelle des informations. Le PDF, par exemple, est un langage qui s’adresse directement à votre imprimante ; il s’intéresse au placement des lignes et des points sur la page, plutôt qu’à des caractères distincts.
Le webscraping : pour quoi faire ?
Tout le monde a déjà été confronté à cette situation : vous allez sur un site web, vous voyez un tableau intéressant et vous essayez de le copier dans Excel pour y apporter des modifications ou l’enregistrer pour plus tard. Mais bien souvent, cela ne marche pas vraiment, ou alors les informations que vous voulez sont réparties sur un grand nombre de sites web. Tout copier à la main peut rapidement s’avérer fastidieux, alors il peut être judicieux d’utiliser un peu de code pour ce faire.
L’avantage du scraping, c’est que vous pouvez le faire avec n’importe quel site web, des prévisions météorologiques aux dépenses gouvernementales, même si le site web en question n’offre pas d’API pour accéder aux données brutes.
Ce que vous pouvez extraire
Le scraping présente bien sûr quelques limites. Certains facteurs peuvent compliquer la capture d’un site web, notamment :
-
un code HTML mal formaté avec peu ou pas d’informations structurelles (comme les vieux sites web gouvernementaux) ;
-
les systèmes d’authentification censés empêcher tout accès automatique (comme les codes CAPTCHA et les « paywalls », ou péages virtuels) ;
-
les systèmes de session qui utilisent les cookies du navigateur pour conserver une trace
des actions de l’utilisateur ;
-
l’absence de listing complet des éléments et l’impossibilité d’utiliser l’astérisque dans les recherches ;
-
le blocage de l’accès « en masse » par les administrateurs du serveur.
Il peut également exister des barrières juridiques : certains pays reconnaissent des droits relatifs aux bases de données qui peuvent restreindre votre droit à réutiliser des informations publiées en ligne. Parfois, vous pourrez choisir d’ignorer la licence et de le faire quand même – selon votre juridiction, vous pouvez avoir des droits particuliers en tant que journaliste. L’extraction de données gouvernementales librement accessibles ne devrait pas poser de problème, mais mieux vaut s’en assurer avant de les publier. Les organisations commerciales – et certaines ONG – sont souvent moins tolérantes et peuvent essayer de prétendre que vous « sabotez » leurs systèmes. Certaines informations peuvent également enfreindre des lois sur la protection de la vie privée ou l’éthique professionnelle.
Quelques outils de scraping
Il existe de nombreux programmes permettant d’extraire des informations brutes à partir d’un site web, y compris des extensions de navigateur et quelques services web. Selon le navigateur que vous utilisez, des outils comme Readability (qui permet d’extraire le texte d’une page web) ou DownThemAll (qui permet de télécharger de nombreux fichiers en une seule fois) vous aideront à automatiser certaines tâches fastidieuses. L’extension Scraper de Chrome, elle, a été explicitement conçue pour extraire des tableaux de sites web. Des extensions de développeur comme FireBug (pour Firefox – des outils similaires sont intégrés à Chrome, Safari et IE) vous permettront de déterminer la structure exacte d’un site web et de suivre les communications entre votre navigateur et le serveur. ScraperWiki est un site web permettant de coder des scrapers dans divers langages de programmation, notamment Python, Ruby et PHP. Si vous voulez vous lancer dans le scraping sans vous donner la peine de configurer un environnement de programmation sur votre ordinateur, c’est la meilleure manière de procéder. D’autres services web, comme les feuilles de calcul Google et Yahoo! Pipes vous permettront également d’effectuer certaines tâches d’extraction sur d’autres sites web.
Comment fonctionne un webscraper ?
Les Webscrapers sont généralement de petits morceaux de code écrits dans un langage de programmation tel que Python, Ruby ou PHP. Le langage que vous choisirez dépendra largement de la communauté à laquelle vous avez accès : s’il y a quelqu’un dans votre salle de rédaction ou dans votre ville qui travaille déjà avec l’un de ces langages, alors il paraît judicieux de choisir celui-ci.
Si certains des outils prêts à l’emploi mentionnés ci-dessus peuvent être utiles pour commencer, la vraie difficulté du scraping consiste à traiter les bonnes pages et les bons éléments au sein de ces pages pour extraire les informations désirées. Il ne s’agit pas là de programmation, mais de comprendre la structure du site web et de la base de données. Quand il affiche un site web, votre navigateur utilise le plus souvent deux technologies : HTTP, pour communiquer avec le serveur et demander des ressources spécifiques, comme des documents, des images ou des vidéos, et HTML, le langage qui compose les sites web.
L’anatomie d’une page web
Toute page HTML est structurée comme une hiérarchie de boîtes (définies par des « balises » HTML). Une grande boîte contiendra de nombreuses boîtes plus petites – par exemple, un tableau se compose de lignes et de cellules. Il existe de nombreux types de balises qui ont différentes fonctions, pour les tableaux, les images ou les liens. Les balises peuvent également contenir des propriétés supplémentaires (on peut par exemple leur attribuer un identifiant unique) et appartenir à des groupes appelés « classes », qui permettent de cibler et de capturer des éléments individuels dans un document. La clé pour bien scraper consiste à comprendre comment s’organise le document. On peut ensuite, via l’un des programmes exposés ici, dire à l’ordinateur de sélectionner les éléments appropriés dans la page et d’extraire leur contenu. Pour aspirer le contenu de pages web, vous devez apprendre à reconnaître les différents types d’éléments qui peuvent composer un document HTML. Par exemple, l’élément <table>, qui définit un tableau, contient des balises <tr> (table row) qui définissent chaque ligne, celles-ci contenant elles-mêmes des balises <td> (table data) pour chaque cellule. Le type d’élément que vous rencontrerez le plus souvent est <div>, qui représente un bloc de contenu générique. Le plus simple pour vous faire une idée de ces éléments, c’est d’utiliser la barre d’outils pour développeur de votre navigateur1 : ainsi, vous pourrez placer votre curseur sur n’importe quelle partie d’une page web et voir le code sous-jacent.
Les balises fonctionnent comme des serre-livres, délimitant le début et la fin d’une unité. Par exemple, <em> indique le début d’un morceau et texte en italique ou important (emphase) et </em> indique la fin de cette section. Facile.
Un exemple : scraping des incidents nucléaires avec Python
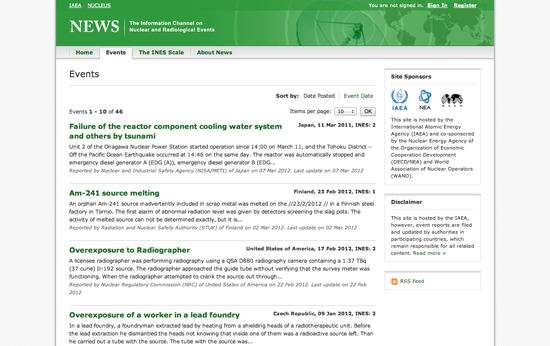
News est le portail de l’Agence internationale de l’énergie atomique (IAEA) consacré aux incidents radioactifs dans le monde (et un sérieux candidat pour l’élection du titre le plus bizarre !). Les incidents sont listés sur une sorte de blog simple dont le contenu peut être facilement aspiré.
Pour commencer, créez un nouveau scraper en Python sur ScraperWiki et vous obtiendrez une boîte de texte pratiquement vide, à part un squelette de code. Dans une autre fenêtre de votre navigateur, ouvrez le site de l’IAEA ainsi que la barre d’outils développeur de votre navigateur. Sous l’onglet Éléments, essayez de trouver l’élément HTML de l’un des titres. La barre d’outils développeur vous aidera à associer les éléments de la page web avec le code HTML sous-jacent.
En étudiant cette page, vous constaterez que les titres sont des éléments <h4< contenus dans une balise <table<. Chaque évènement correspond à une ligne <tr<, qui contient également une description et une date. Pour extraire le titre de tous les évènements, nous devons trouver un moyen de sélectionner chaque ligne du tableau une par une et d’aspirer le texte de chaque titre.
Pour transformer ce processus en code, nous devons d’abord prendre conscience de toutes les étapes que cela implique. Pour s’en faire une idée, jouons à un jeu très simple : dans votre fenêtre ScraperWiki, essayez d’écrire des instructions individuelles vous-même, pour chaque tâche que votre scraper doit accomplir, comme les étapes d’une recette (faites précéder chaque ligne du signe dièse pour indiquer à Python qu’il ne s’agit pas de code, mais d’un commentaire). Par exemple :
# Chercher toutes les lignes du tableau # Extraire le titre de chaque ligne.
Essayez d’être aussi précis que possible et partez du principe que le programme ne sait rien de la page que vous essayez d’aspirer.
Une fois que vous avez écrit un peu de pseudo-code, comparons-le au code principal de notre premier scraper :
import scraperwiki from lxml import html
Dans cette première section, nous importons les fonctionnalités de librairies existantes – des bouts de code pré-écrits. ScraperWiki nous permettra de télécharger des sites web, alors que lxml est un outil permettant l’analyse structurée de documents HTML. Bonne nouvelle : si vous écrivez un scraper en Python avec ScraperWiki, ces deux lignes seront toujours les mêmes.
Ensuite, le code définit la variable url et lui attribue l’adresse de la page de l’IAEA comme valeur. Notez que l’URL elle-même est entre guillemets car elle ne fait pas partie du code : c’est une chaîne ou séquence de caractères.
url = «http://www-news.iaea.org/EventList.aspx» doc_text = scraperwiki.scrape(url) doc = html.fromstring(doc_text)
Nous insérons ensuite la variable URL dans la fonction scraperwiki.scrape. Une fonction exécute une tâche prédéfinie – celle-ci télécharge la page web, puis copie le résultat dans une autre variable, doc_text. doc_text contiendra alors le texte du site web ; pas la forme visuelle que vous voyez sur le site web, mais le code source, comprenant toutes les balises. Comme ce format est difficile à analyser, nous allons utiliser une autre fonction, html.fromstring, pour générer une représentation spéciale qui nous permettra de traiter facilement chaque élément, appelée Document Object Model (DOM).
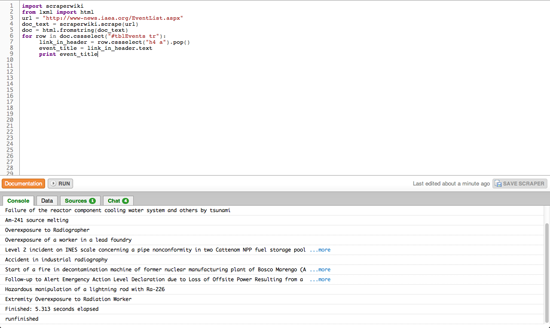
for row in doc.cssselect(«#tblEvents tr»): link_in_header = row.cssselect(«h4 a»).pop() event_title = link_in_header.text print event_title
Dans cette dernière étape, nous utilisons le DOM pour trouver chaque ligne de notre tableau et extraire le titre de l’évènement. On utilise ici deux nouveaux concepts : la boucle « for » et la sélection d’éléments (.cssselect). La boucle « for » parcourt une liste d’éléments, attribuant à chacun un nom temporaire (« row » dans ce cas), puis exécute les instructions indentées pour chaque élément.
L’autre nouveau concept, la sélection d’éléments, utilise un langage spécial pour trouver des éléments dans le document. On utilise généralement des sélecteurs CSS pour ajouter des informations de mise en page dans des balises HTML, et ceux-ci peuvent servir à sélectionner des éléments précis sur une page. Dans ce cas (ligne 6), nous sélectionnons #tblEvents tr, qui associera chaque <tr> du tableau à l’identifiant tblEvents (le signe dièse indique simplement un identifiant). Notez que cela renverra non pas une seule ligne (<tr>) mais une liste d’éléments <tr>.
On peut le voir à la ligne suivante (ligne 7), où l’on applique un autre sélecteur pour trouver tous les <a> (à savoir les hyperliens) contenus dans des <h4> (les titres). Ici, nous voulons conserver un seul élément (il n’y a qu’un seul titre par ligne) ; nous devons donc le détacher du sommet de la liste renvoyée par notre sélecteur à l’aide de la fonction .pop().
Notez que certains éléments du DOM contiennent du vrai texte (qui ne fait pas partie du balisage), auquel nous pouvons accéder en utilisant la syntaxe élément.text vue à la ligne 8. Pour finir, à la ligne 9, nous imprimons ce texte dans la console ScraperWiki. Si vous appuyez sur Run dans votre scraper, la petite fenêtre devrait maintenant commencer à lister le nom des évènements extraits du site de l’IAEA.
Vous pouvez maintenant voir le fonctionnement d’un scraper de base : il télécharge la page web, la convertit au format DOM, puis vous permet de sélectionner et d’extraire le contenu de votre choix. À partir de ce squelette, vous pouvez essayer de résoudre certains des problèmes restants à l’aide de la documentation de ScraperWiki et de Python.
-
Pouvez-vous trouver l’adresse du lien dans chaque titre d’évènement ?
-
Pouvez-vous sélectionner la petite boîte qui contient la date et le lieu en utilisant son nom de classe CSS et extraire le texte de l’élément ?
-
ScraperWiki offre une petite base de données avec chaque scraper pour stocker les résultats ; copiez l’exemple que vous trouverez dans sa documentation et adaptez-le pour qu’il sauvegarde le titre, le lien et la date des évènements.
-
La liste des évènements comporte de nombreuses pages ; pouvez-vous aspirer plusieurs pages pour récupérer également les évènements passés ?
Pendant que vous essayez de résoudre ces défis, faites le tour de ScraperWiki : il y a de nombreux exemples de scrapers existants et, bien souvent, les données qu’ils contiennent sont très intéressantes en elles-mêmes. Ainsi, vous n’aurez pas besoin de démarrer votre scraper de zéro : choisissez-en un qui vous paraît convenir à vos besoins, copiez-le et adaptez-le à votre problème.
Friedrich Lindenberg, Open Knowledge Foundation