Le Web comme source de données
Comment trouver plus d’informations sur quelque chose qui n’existe que sur Internet ? Qu’il s’agisse d’une adresse mail, d’un site web, d’une image ou d’un article Wikipédia, nous allons voir quels outils vous permettront d’en savoir plus.
Les outils web
Tout d’abord, voici quelques services que vous pouvez utiliser pour en savoir plus sur un site entier.
Whois
En allant à l’adresse whois.domaintools.com (ou en tapant simplement « whois www.exemple.com » dans le terminal sur un Mac, en remplaçant l’URL par celle de votre choix), vous obtiendrez les données d’enregistrement de n’importe quel site web. Ces dernières années, certains propriétaires ont choisi des méthodes d’enregistrement anonymes, mais bien souvent, vous trouverez le nom, l’adresse, le mail et le numéro de téléphone de la personne ayant enregistré le site web. Vous pouvez également saisir des adresses IP numériques et obtenir des données sur l’organisation ou l’individu qui possède le serveur. C’est particulièrement pratique quand vous essayez de trouver des informations sur un utilisateur abusif ou malveillant d’un service, car la plupart des sites web conservent l’adresse IP de toutes les personnes qui y accèdent.
Blekko
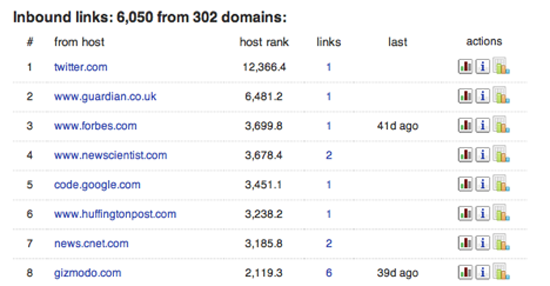
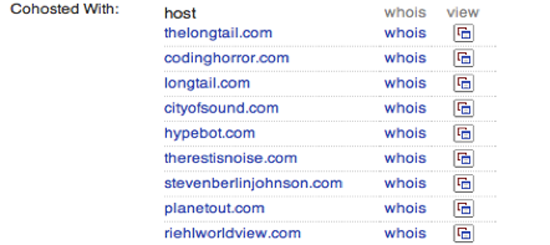
Le moteur de recherche Blekko offre une quantité incroyable d’informations grâce aux statistiques internes qu’il collecte en parcourant le Web. Si vous entrez un nom de domaine suivi de « /seo », vous obtiendrez une page d’informations sur cette URL. Le premier onglet (figure ci-dessous) vous montre quels autres sites renvoient vers le domaine par ordre de popularité. Cela peut s’avérer extrêmement utile pour comprendre quelle couverture reçoit un site, et pourquoi il est si bien classé dans les résultats de recherche de Google, puisque ceux-ci sont basés sur ces mêmes liens entrants. Sur la capture d’écran ci-dessous, vous pouvez voir quels autres sites web tournent sur la même machine. Il est courant pour les scammers et les spammers de se forger une crédibilité en construisant plusieurs sites qui renvoient les uns vers les autres. On dirait des domaines indépendants, et ils peuvent même avoir des détails d’enregistrement différents, mais bien souvent, ils se trouvent sur le même serveur parce que c’est l’option la plus économique. Ces statistiques vous donneront une idée de la structure commerciale cachée du site que vous étudiez.
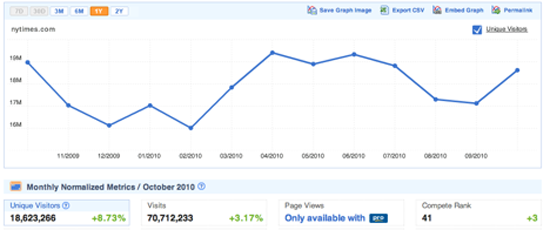
Compete.com
En sondant un échantillon représentatif des consommateurs américains, http://www. compete.com/ établit des statistiques d’utilisation détaillées pour la plupart des sites web, et certains détails de base sont disponibles gratuitement. Sélectionnez l’onglet Site Profile et saisissez un nom de domaine (illustration ci-dessous). Vous verrez alors un graphique détaillant le trafic du site au cours de l’année passée, ainsi que des statistiques sur le nombre et la régularité des visites. Comme ils sont basés sur des sondages, ces chiffres ne sont que des approximations, mais j’ai pu constater qu’ils étaient relativement précis quand j’ai eu l’occasion de les comparer avec des statistiques internes. Il semblerait que ce soit notamment une bonne source pour comparer deux sites, car même si les valeurs absolues peuvent être inexactes pour les deux, elles donnent tout de même une bonne idée de leur différence relative en termes de popularité. En revanche, ce site ne sonde que les consommateurs américains, alors peu de données seront disponibles pour les sites principalement internationaux.
Recherche ciblée avec Google
Une fonctionnalité qui peut s’avérer extrêmement utile pour explorer le contenu d’un domaine particulier est le mot-clef « site: ». Si vous ajoutez « site:exemple.com » à vos termes de recherche, Google renverra uniquement les résultats hébergés sur le site spécifié. Vous pouvez préciser votre recherche en incluant le préfixe des pages qui vous intéressent, par exemple « site:exemple.com/pages/ », et vous obtiendrez uniquement les résultats correspondants. Cela peut s’avérer utile pour trouver les informations que le propriétaire du domaine a mises en ligne par mégarde mais qu’il ne tient pas à diffuser ; en choisissant les bons mots-clefs, vous trouverez peut-être des informations très révélatrices.
Rechercher des pages web, des images et des vidéos
Parfois, vous vous intéresserez à l’activité entourant une histoire particulière plutôt qu’à un seul site web. Les outils ci-dessous vous aideront à mieux percevoir comment les gens lisent, réagissent, copient et partagent le contenu sur le Web.
Bit.ly
Je me tourne toujours vers bit.ly quand je veux savoir comment les gens partagent un lien en particulier. Pour l’utiliser, saisissez l’URL qui vous intéresse, puis cliquez sur le lien Info Page+. Vous serez redirigé vers la page des statistiques complètes (vous devrez peut-être commencer par sélectionner « aggregate bit.ly link » si vous êtes identifié au service). Cela vous donnera une meilleure idée de la popularité de la page, notamment de son activité sur Facebook et Twitter, et vous trouverez en-dessous les conversations publiques sur le lien en question fournies par backtype.com. Je trouve cette combinaison de données de trafic et de conversations très utile pour comprendre pourquoi tel site ou telle page est populaire, et quelles sont les personnes qui y contribuent.
Le service de micro-blogging étant de plus en plus utilisé, il est de plus en plus utile pour jauger comment les gens partagent et débattent du contenu. Il est extrêmement simple de trouver des conversations publiques sur un lien. Il suffit de copier l’URL qui vous intéresse dans la zone de recherche, puis de cliquer sur « more tweets » pour voir la liste de résultats complète.
Cache de Google
Quand une page prête à controverse, ses publicateurs peuvent décider de la supprimer ou de la modifier sans préavis. Si vous suspectez que c’est le cas, la première chose à faire consiste à consulter le cache de Google. La fréquence des mises à jour est en constante augmentation, alors vous aurez plus de chances en essayant dans les heures qui suivent les changements suspectés. Saisissez l’URL cible dans le champ de recherche de Google, puis cliquez sur la triple flèche à droite du résultat. Un aperçu graphique devrait apparaître, et si vous avez de la chance, il y aura un petit lien « Cache » au sommet. Cliquez dessus pour voir la capture de la page réalisée par Google lors de la dernière indexation. Si la page a du mal à se charger, vous pouvez basculer vers une version plus basique comprenant uniquement le texte en cliquant sur un autre lien au sommet de la page. Vous avez intérêt à prendre une capture d’écran ou à sauvegarder tout le contenu pertinent, car il risque d’être invalidé à tout moment par une nouvelle indexation.
Internet Archive : la machine à remonter le temps
Si vous avez besoin de suivre l’évolution d’une page sur une longue période, plusieurs mois ou plusieurs années, l’Internet Archive offre un service appelé The Wayback Machine qui capture périodiquement le contenu des pages les plus populaires du Web. Vous allez sur le site, vous saisissez le lien que vous souhaitez étudier, et s’il existe des copies, vous aurez la possibilité de sélectionner la date voulue dans un calendrier. Vous verrez alors une copie approximative de la page telle qu’elle était à ce moment-là. Il manquera souvent des éléments de style ou des images, mais cela suffit généralement à se faire une idée du contenu de la page.
Code source
C’est peut-être faire preuve d’optimisme, mais les développeurs laissent souvent des commentaires ou d’autres indices dans le code HTML. Tous les navigateurs offrent une option permettant de voir le code source brut d’une page. Pas besoin d’être un expert en programmation pour repérer les petits bouts de texte qui peuvent se balader. Même s’il s’agit uniquement d’un avis de copyright ou du nom de l’auteur, ces informations peuvent souvent donner des indices importants sur la création et le but de la page.
TinEye
Parfois, vous voulez vraiment connaître la source d’une image, mais sans légende claire, il n’existe aucun moyen évident de la retrouver avec des moteurs de recherche traditionnels comme Google. TinEye est un moteur de recherche d’images inversé : vous lui donnez l’image que vous avez, et il trouve d’autres images qui lui ressemblent sur le Web. Comme il utilise un algorithme de reconnaissance d’image pour établir des correspondances, il fonctionne même quand une copie a été recadrée, déformée ou compressée. Cela peut s’avérer extrêmement efficace quand vous suspectez qu’une image est présentée à tort comme originale ou nouvelle, car vous pouvez ainsi remonter à la source.
YouTube
Si vous cliquez sur l’icône Statistiques dans le coin inférieur droit de n’importe quelle vidéo, vous obtiendrez quantité d’informations sur l’évolution de son public au fil du temps. Bien qu’elles ne soient pas complètes, ces statistiques sont utiles pour se faire une idée de qui sont les visiteurs, d’où ils viennent et quand.
Faire parler les emails
Si vous analysez des emails, vous voudrez généralement avoir plus de détails sur l’identité et l’emplacement de l’expéditeur. Il n’existe aucun bon outil prêt à l’emploi pour ce faire, mais il peut être très utile de connaître les bases des en-têtes cachés inclus dans chaque mail. Ces en-têtes fonctionnent comme des cachets postaux, et peuvent révéler une quantité surprenante d’informations sur l’expéditeur. Ils comprennent bien souvent l’adresse IP de la machine depuis laquelle le mail a été envoyé, que vous pouvez ensuite passer au « whois » pour savoir à quelle organisation elle appartient. S’il s’avère que c’est un FAI public, vous pouvez alors utiliser MaxMind pour obtenir son emplacement approximatif.
Pour voir ces en-têtes dans Gmail, ouvrez le message, déroulez le menu à côté du bouton Répondre, en haut à droite, puis cliquez sur Afficher l’original.
Vous verrez alors une nouvelle page révélant le contenu caché. Il devrait y avoir deux douzaines de lignes au début qui se finissent par un point-virgule. L’adresse IP que vous cherchez peut se trouver là-dedans, mais son nom dépendra de la façon dont l’email a été envoyé. S’il a été envoyé depuis Hotmail, l’adresse se trouvera dans « X-OriginatingIP: », mais s’il provient d’Outlook ou de Yahoo!, elle se trouvera dans la première ligne commençant par « Received: ».
En passant une adresse IP au « whois », j’apprends qu’elle est attribuée à Virgin Media, un FAI anglais, alors je la saisis dans le service de géo-localisation MaxMind pour découvrir qu’elle se trouve dans ma ville natale de Cambridge. Je peux donc être raisonnablement sûr qu’il s’agit bien de mes parents qui m’écrivent et pas d’imposteurs !
Les tendances
Si vous enquêtez sur un sujet général plutôt qu’un site ou un élément particulier, voici quelques outils qui pourront vous apporter plus d’informations.
Trafic des articles Wikipédia
Si vous voulez voir comment l’intérêt public autour d’un sujet ou d’une personne évolue au fil du temps, vous pouvez obtenir les statistiques de visite de Wikipédia jour par jour sur http://stats.grok.se/. Le site est un peu brut de décoffrage, mais vous pourrez trouver les informations dont vous avez besoin en creusant un peu. Saisissez le nom qui vous intéresse pour obtenir une vue mensuelle du trafic de cette page. Vous obtiendrez un graphique présentant le nombre de visites de la page pour chaque jour du mois spécifié. Malheureusement, il n’est possible de voir qu’un seul mois à la fois. Pour suivre des changements à plus long terme, vous devrez sélectionner un nouveau mois et relancer la recherche.
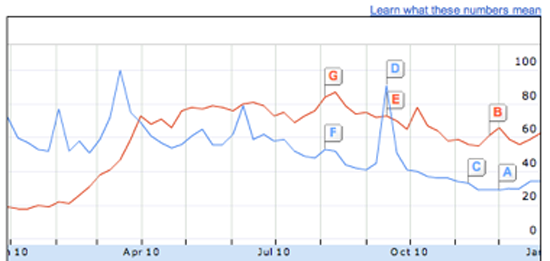
Google Trends
Vous pouvez avoir un aperçu des recherches les plus populaires à l’aide de Google Trends. Saisissez deux recherches courantes, comme « Justin Bieber vs Lady Gaga », et vous obtiendrez un graphique comparant l’évolution de leur nombre de recherches respectifs. De nombreuses options permettent d’affiner la recherche, de cibler une zone géographique ou une période particulière. La seule limite, c’est le manque de valeurs absolues – on n’obtient que des pourcentages relatifs, qui peuvent être difficiles à interpréter.
Pete Warden, analyste de données et développeur indépendant