Aspirer les données d’Ameli
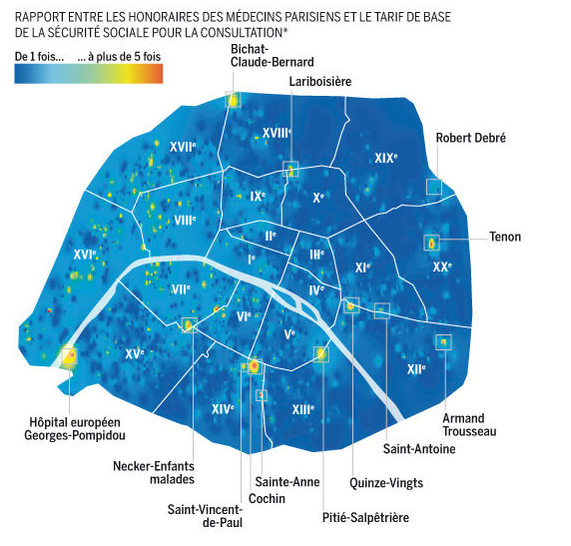
À partir du moment où des informations sont diffusées sur Internet, il devient plus ou moins facile de les recueillir à grande échelle. C’est ce qui fut fait pour les tarifs des médecins, que l’Assurance Maladie diffuse à destination des assurés.
Le site ameli-direct.fr propose, pour chaque médecin, une fiche permettant de connaître les tarifs habituellement pratiqués pour différents actes, les éventuels dépassements d’honoraires ainsi que le secteur de conventionnement, aux côtés d’informations plus traditionnelles comme l’adresse et le numéro de téléphone. Le débat autour des dépassements d’honoraires n’était jusqu’alors alimenté que par les données agrégées que la Sécu voulait bien mettre à disposition des journalistes. Cette base de données en ligne devenait donc une source intéressante.
Le site renvoyait des résultats à partir d’un formulaire de recherche, en Flash. La requête passait ensuite dans une page HTML, non visible, avant de renvoyer une liste de résultats, limités à 500 : « Plus de 500 résultats : veuillez préciser votre recherche. » Après avoir vérifié que l’interface en Flash ne renvoyait aucun fichier par le biais de l’inspecteur web (disponible sur Chrome et Firefox en faisant un clic droit puis en cliquant sur Inspecter l’élément.), nous avons concentré nos forces sur le fichier recherche.html. Celui-ci déposait sur l’ordinateur du visiteur plusieurs cookies, obligatoires pour afficher les résultats, ce que l’on pouvait découvrir dans le header du fichier, toujours dans l’inspecteur web. Le programme que nous avons développé pour aspirer les données devait donc avoir des paramètres de recherche suffisamment précis pour ne pas renvoyer plus de 500 fiches médecins, et accepter les cookies. Il devait également retenir un chiffre, différent à chaque fois, qui dépendait des cookies et permettait la création des URL des fiches-médecins. Nous avons décidé de limiter nos recherches aux consultations dans les dix plus grandes villes de France, pour englober l’ensemble des spécialités. Dans certains arrondissements de Paris, nous cherchions d’abord les femmes, puis les hommes, pour ne pas atteindre les 500 résultats. La liste de résultats obtenue permettait de récupérer une première salve d’informations, dont l’identifiant unique du médecin, présent dans l’URL de la fiche. Pour chacun des professionnels sauvegardés dans la base, il fallait ensuite accéder à la page HTML du médecin pour récupérer les informations complémentaires.
Au rythme d’une fiche-médecin par seconde, les quelques 5 000 médecins parisiens furent traités pendant une nuit, sans que nous n’ayons eu à craindre une limitation d’IP par les services de la Sécu. Les données récupérées ont ensuite pu être analysées, géocodées et représentées sur une carte, montrant par exemple qu’en moyenne, le dépassement d’honoraire est de 15 euros pour une consultation à Paris.
Alexandre Léchenet, Le Monde