Qu’est-ce que le datajournalisme ?
Qu’est-ce que le datajournalisme ? Je pourrais simplement répondre que c’est du journalisme de données. Mais cela ne nous avancerait pas beaucoup.
Les mots « données » et « journalisme » sont tous deux des mots à sens multiples. Certaines personnes voient les « données » comme un paquet de nombres, le plus souvent regroupés sur une feuille de calcul. Il y a 20 ans, c’était à peu près le seul genre de données auquel les journalistes avaient affaire. Mais nous vivons aujourd’hui dans un monde numérique, un monde dans lequel pratiquement tout peut être (et est de fait) décrit par des chiffres. Votre expérience professionnelle, 300 000 documents confidentiels, votre cercle d’amis, tout peut être décrit avec simplement deux chiffres : des zéros et des uns. Les photos, les vidéos et les sons sont tous décrits avec ces deux mêmes chiffres. Les meurtres, la maladie, les résultats électoraux, la corruption et le mensonge : des uns et des zéros. Qu’est-ce qui distingue le datajournalisme du journalisme traditionnel ? C’est peut-être les nouvelles possibilités qui s’ouvrent quand on combine un instinct journalistique traditionnel avec l’énorme quantité et diversité d’informations numériques aujourd’hui disponibles.
Et ces possibilités peuvent survenir à chaque étape du processus journalistique : en utilisant par exemple un langage de programmation pour automatiser le processus de collecte et de recoupement d’informations provenant des instances locales, de la police et d’autres sources civiles, comme l’a fait Adrian Holovaty avec Chicago Crime puis EveryBlock.
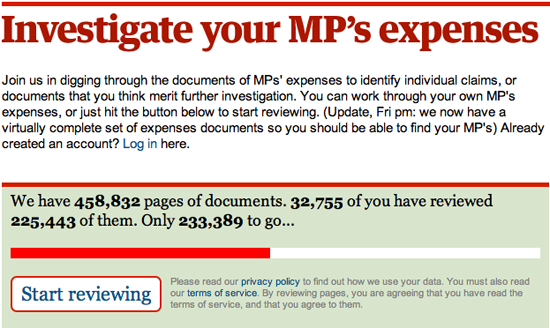
Ou en se servant d’un logiciel pour établir des liens entre des centaines de milliers de documents, comme l’a fait le The Telegraph avec les notes de frais des députés britanniques. Le datajournalisme peut permettre de raconter une histoire complexe avec des graphiques clairs. Citons par exemple les discours spectaculaires de Hans Rosling sur la visualisation de la pauvreté mondiale avec Gapminder, visionnés par des millions de personnes à travers le monde. Ou encore le travail de David McCandless (_Information is Beautiful_) sur la condensation de gros nombres – la contextualisation des dépenses publiques ou l’analyse de la pollution générée et évitée par l’éruption du volcan islandais –, qui démontre l’importance d’un design clair.
Il peut également aider à expliciter l’impact d’une histoire sur chaque individu, comme le font maintenant régulièrement la BBC et The Financial Times avec leurs budgets interactifs (qui permettent de voir comment le budget vous affecte personnellement). Et il permet également d’ouvrir le processus de collecte d’informations lui-même, comme le fait si bien The Guardian en partageant des données, des éléments de contexte et des questions sur son Datablog.
Les données peuvent être la source du datajournalisme, elles peuvent être l’outil qui permet de raconter l’histoire – ou elles peuvent être les deux. Comme n’importe quelle source, elles doivent être traitées avec scepticisme ; et comme n’importe quel outil, nous devons prendre conscience de leurs limites et de leur influence sur la forme des histoires qu’elles nous permettent de créer.
Paul Bradshaw, Birmingham City University