Utiliser la visualisation pour faire parler les données
La visualisation est un aspect essentiel de l’analyse de données. Elle offre une ligne d’attaque frontale, révèle la structure complexe de données qui ne pourraient être comprises d’aucune autre façon. Elle permet de découvrir des résultats inattendus et de remettre en question les conclusions attendues.
William S. Cleveland (in Visualizing Data, Hobart Press, 1993)
Les données elles-mêmes, composées de bits et d’octets stockés dans un fichier sur un disque dur, sont invisibles. Pour pouvoir voir et comprendre ces données, nous devons les visualiser. Dans cette section, je parlerai de visualisation au sens large, en incluant également les représentations de données purement textuelles. Par exemple, le simple fait de charger une base de données dans un tableur peut être considéré comme une visualisation. Les données invisibles se transforment soudainement en une « image » visible sur notre écran. Ainsi, la question n’est pas de savoir si les journalistes doivent visualiser les données ou non, mais quel type de visualisation est le plus utile selon la situation.
En d’autres termes : quand est-il nécessaire de créer une visualisation plus complexe qu’un simple tableau ? La réponse courte est : presque toujours. De simples tableaux ne sont clairement pas suffisants pour donner une bonne vue d’ensemble d’une base de données, et ils ne permettent pas d’identifier immédiatement les tendances au sein des données. Par exemple, des tendances géographiques ne peuvent être représentées que sur une carte.
Mais il existe également d’autres solutions, que nous étudierons dans la suite de cette section.
Visualiser pour trouver des idées
Il est utopique de penser que les outils et les techniques de visualisation de données feront magiquement apparaître un tas d’histoires toutes cuites. Il n’y a pas de règles, pas de « protocole » qui vous garantira de trouver un angle. Il me semble plus judicieux de chercher des « indices », des informations qu’un journaliste talentueux saura tisser pour donner forme à des histoires.
Chaque nouvelle visualisation est susceptible de nous apporter des informations sur nos données. Certaines sont peut-être déjà connues (mais peut-être pas encore prouvées), alors que d’autres peuvent être complètement nouvelles, voire surprenantes. Certaines de ces informations pourront donner naissance à un article, d’autres s’avéreront être le produit de données erronées, que des visualisations sont susceptibles de faire apparaître. Pour mieux faire parler les données, le processus décrit ci-dessous (et dans le reste de cette section) m’a été d’une aide précieuse.
Apprendre à visualiser des données
La visualisation offre un point de vue unique sur une base de données. Il existe de nombreuses manières de visualiser des données.
Les tableaux sont très puissants quand vous avez relativement peu de données à visualiser. Ils présentent les en-têtes et les montants de la façon la plus structurée et organisée qui soit et révèlent leur véritable potentiel quand on les combine avec la possibilité de trier et de filtrer les données. Par ailleurs, Edward Tufte suggère d’inclure de petits bouts de graphiques dans les tableaux – par exemple, une barre par colonne ou un graphique de tendance (sparkline). Mais il reste que les tableaux sont limités. Ils sont parfaits pour afficher des variables unidimensionnelles, comme un top 10, mais ils s’avèrent insuffisants pour comparer plusieurs dimensions en même temps (par exemple, l’évolution de la population de plusieurs pays au fil du temps).
De manière générale, les graphiques permettent d’associer certains aspects de vos données aux propriétés visuelles de formes géométriques. On a beaucoup écrit sur l’efficacité de ces différentes propriétés visuelles, et pour résumer, on pourrait dire ceci : la couleur est difficile à rendre parlante, le positionnement fait tout. Dans un diagramme de dispersion, par exemple, deux dimensions sont associées à des axes x et y. Vous pouvez même illustrer une troisième dimension en utilisant la couleur ou en jouant sur la taille des symboles affichés. Les graphiques linéaires sont particulièrement adaptés à la présentation d’une évolution chronologique, alors que les diagrammes en bâtons sont parfaits pour comparer des données classées par catégorie. Vous pouvez également superposer plusieurs graphiques. Si vous voulez comparer plusieurs groupes de données, une excellente solution consiste à afficher plusieurs versions du même graphique. Dans chaque graphique, vous pouvez utiliser différentes échelles pour explorer divers aspects de vos données (échelle linéaire ou logarithmique par exemple).
En fait, l’essentiel des données auxquelles nous avons affaire sont liées d’une manière ou d’une autre à de vraies personnes. Le pouvoir des cartes réside donc dans leur capacité à relier les données à notre monde bien physique. Imaginez une base de données de géolocalisation des crimes. Le principal intérêt est de voir où les crimes se produisent. Les cartes peuvent également révéler des relations géographiques au sein des données (par exemple, une tendance nord/sud ou zones urbaines/zones rurales).
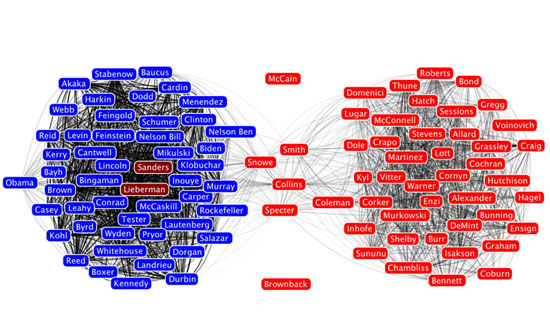
En parlant de relations, le quatrième type de visualisation le plus important est le graphe. Les graphes permettent d’afficher les liens (arêtes) entre vos points de données (nœuds). La position des nœuds est ensuite calculée par des algorithmes de présentation plus ou moins complexes qui permettent de voir immédiatement la structure du réseau. L’astuce pour un graphe réussi, c’est de trouver un bon moyen de modéliser le réseau lui-même. Toutes les bases de données n’incluent pas de relations, et même quand c’est le cas, il ne s’agit pas forcément de l’aspect le plus intéressant à étudier. Parfois, c’est au journaliste de définir les arêtes qui relient les nœuds. Un exemple parfait est ce graphe social des sénateurs américains, dont les arêtes relient les sénateurs qui votent dans le même sens plus de 65 % du temps.
Une fois que vous avez visualisé vos données, vous devez tirer un enseignement de l’image que vous avez créée. Vous pouvez vous poser les questions suivantes.
- Que vois-je dans cette image ? Est-ce conforme à mes attentes ?
- Y a-t-il des tendances intéressantes ?
- Que cela signifie-t-il dans le contexte des données ?
Parfois, vous finirez peut-être avec une visualisation qui, en dépit de sa beauté, ne vous dira rien d’intéressant sur vos données. Mais il y a presque toujours quelque chose à apprendre d’une visualisation, aussi triviale soit-elle.
Documenter ses découvertes et les étapes du processus
Si vous voyez ce processus comme un voyage à travers la base de données, la documentation est votre carnet de bord. Elle relatera où vous avez voyagé, ce que vous avez vu, et comment vous avez pris des décisions à chaque étape. Vous pouvez même commencer à documenter votre travail avant de regarder les données.
Dans la plupart des cas, quand nous travaillons sur une base de données jamais vue auparavant, nous partons déjà avec plein d’attentes et de suppositions. Il y a généralement une raison à ce que nous nous intéressions à une base de données particulière. Il peut être judicieux de commencer par noter ces pensées initiales, afin d’identifier nos a priori et de réduire le risque de mal interpréter les données en ne cherchant que ce que l’on voulait trouver à l’origine.
Je pense vraiment que la documentation est l’étape la plus importante du processus – et c’est également celle que nous négligeons le plus souvent. Comme vous le verrez dans l’exemple ci-après, le processus décrit implique beaucoup de démêlage et de traitement de données. Vous pouvez être perdu devant 15 graphiques que vous avez créés, surtout s’il s’est écoulé un certain temps depuis leur création. En fait, ces graphiques ne seront utiles (à vous ou toute autre personne à qui vous souhaitez communiquer vos découvertes) que s’ils sont présentés dans le contexte dans lequel ils ont été créés. C’est pourquoi vous devez prendre le temps de noter plusieurs choses par écrit, comme suit.
- Pourquoi ai-je créé ce graphique ?
- Qu’ai-je fait avec les données pour le créer ?
- Que me dit ce graphique ?
Transformer les données
Naturellement, avec les indices que vous aura apportés la dernière visualisation, vous aurez peut-être une idée de ce que vous voulez voir ensuite. Vous aurez peut-être remarqué des tendances intéressantes dans la base de données que vous voudrez inspecter plus en détail.
Les transformations possibles sont les suivantes.
- L’agrandissement, pour étudier certains détails de la visualisation.
- L’agrégation, pour combiner de nombreuses données en un seul groupe.
- Le filtrage pour exclure (temporairement) les données ne répondant pas à notre angle principal.
- La suppression des valeurs aberrantes, pour se débarrasser des données nonreprésentatives de 99 % de la base de données.
Supposons que vous ayez créé un graphe, et que le résultat n’est rien d’autre qu’un amas de nœuds reliés par des centaines d’arêtes (un résultat courant quand on visualise ce que l’on appelle des « réseaux denses »). Une étape de transformation classique consisterait à filtrer certaines des arêtes. Si, par exemple, les arêtes représentent des flux d’argent entre pays, nous pouvons exclure tous les flux inférieurs à un certain montant.
Quels outils utiliser ?
La question des outils à utiliser n’est pas évidente. Chaque outil de visualisation de données disponible présente des avantages et des inconvénients. La visualisation et le traitement de données doit être simple et bon marché. Si vous passez des heures à changer les paramètres de vos visualisations, vous n’expérimenterez pas beaucoup. Cela ne veut pas nécessairement dire que vous ne devez pas apprendre à vous servir de l’outil. Mais une fois que vous avez appris, cela doit être vraiment efficace.
Il est souvent préférable de choisir un outil qui couvre à la fois le traitement et la visualisation des données. En répartissant les tâches dans plusieurs outils, vous devrez importer et exporter vos données fréquemment. Voici une petite liste de quelques outils de traitement et de visualisation de données :
- les tableurs comme LibreOffice, Excel ou Google Docs ;
- les frameworks de programmation statistique comme R (r-project.org) ou Pandas (pandas.pydata.org) ;
- les systèmes d’information géographique (SIG) comme Quantum GIS, ArcGIS ou GRASS ;
- les librairies de visualisations comme d3.js (mbostock.github.com/d3), Prefuse (prefuse.org) ou Flare (flare.prefuse.org) ;
- les outils de traitement de données comme Google Refine ou Datawrangler ;
- les logiciels de visualisation sans programmation comme ManyEyes ou Tableau Public (tableausoftware.com/products/public).
Les exemples de visualisation de la section suivante ont été créés à l’aide de R, qui est une sorte de couteau suisse de la visualisation (scientifique) de données.
Un exemple : comprendre les données de financement des campagnes électorales aux États-Unis
Jetons un œil à la base de données de financement de la campagne présidentielle américaine, qui contient environ 450 000 dons versés aux candidats à la présidentielle américaine. Le fichier CSV fait 60 mégaoctets et est beaucoup trop gros pour un logiciel comme Excel.
Dans la première étape, je noterai explicitement mes hypothèses initiales sur la base de données de la Federal Election Commission:
- Obama reçoit le plus de dons (puisqu’il est le président en fonction et qu’il est le plus populaire).
- Le nombre de dons augmente à mesure que la date des élections se rapproche.
- Obama reçoit plus de petits dons que les candidats républicains.
Pour répondre à la première question, nous devons transformer les données. Au lieu d’étudier chaque contribution individuelle, nous devons additionner les montants totaux versés à chaque candidat. Après avoir visualisé et trié les résultats dans un tableau, nous pouvons confirmer que c’est bien Obama qui reçoit le plus de dons :
| Candidat | Montant ($) |
|---|---|
| Obama, Barack | 77 453 620,39 |
| Romney, Mitt | 50 372 334,87 |
| Perry, Rick | 18 529 490,47 |
| Paul, Ron | 11 844 361,96 |
| Cain, Herman | 7 010 445,99 |
| Gingrich, Newt | 6 311 193,03 |
| Pawlenty, Timothy | 4 202 769,03 |
| Huntsman, Jon | 2 955 726,98 |
| Bachmann, Michelle | 2 607 916,06 |
| Santorum, Rick | 1 413 552,45 |
| Johnson, Gary Earl | 413 276,89 |
| Roemer, Charles E. Buddy III | 291 218,80 |
| McCotter, Thaddeus G | 37 030,00 |
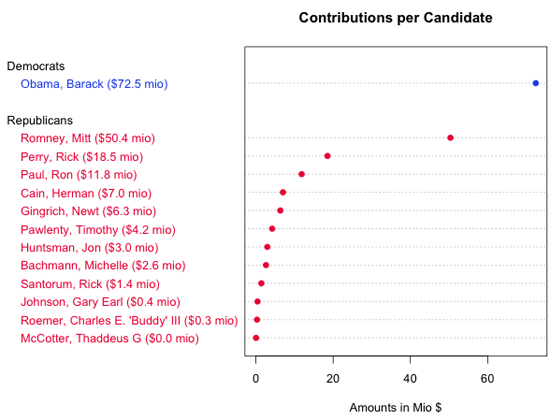
Ce tableau nous présente les montants par ordre décroissant, mais il ne nous dit pas grandchose des tendances sous-jacentes du classement. La figure ci-dessous est une autre visualisation des données, un type de graphique « à points », sur lequel on peut voir tout ce qui est affiché dans le tableau plus les tendances au sein du champ. Par exemple, le graphique à points nous permet de comparer immédiatement la distance entre Obama et Romney, ou Romney et Perry, sans avoir à soustraire les valeurs. (Remarque : ce graphique à points a été créé avec R. Vous trouverez des liens vers le code source à la fin de ce chapitre.)
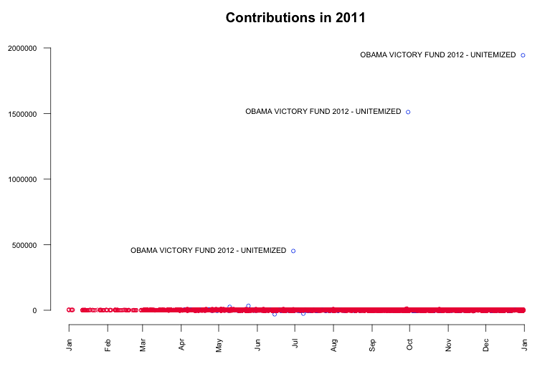
Poursuivons maintenant avec une vision plus générale de la base de données. Comme première étape, j’ai visualisé tous les dons à l’aide d’un graphique simple. On peut voir que pratiquement tous les dons sont très, très petits par rapport aux trois exceptions notables. En y regardant de plus près, on peut voir que ces contributions exceptionnelles proviennent de l’organisation de soutien Obama Victory Fund 2012 (une super PAC) et ont été versées le 29 juin 2011 (450 000 $), le 29 septembre 2011 (1,5 million $) et le 30 décembre 2011 (1,9 million $).
Les dons des Super PAC en eux-mêmes sont sans doute l’angle le plus évident que présentent les données, mais il peut également être intéressant d’étudier le reste. Comme ces grosses contributions perturbent notre vision des plus petits dons réalisés par des individus, nous allons les exclure des données. Cette transformation est couramment appelée suppression des valeurs aberrantes. En reproduisant à nouveau la visualisation, on peut voir que la plupart des dons se situent dans une fourchette allant de 10 000 à -5 000 $.
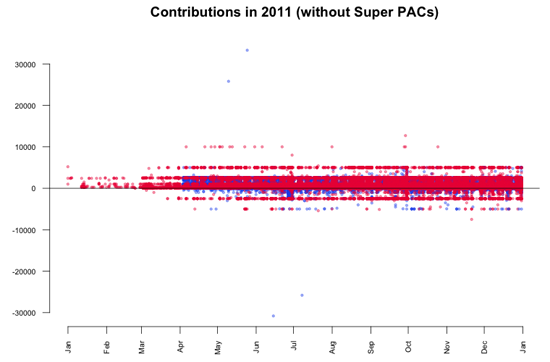
Conformément aux limites fixées par la FECA (loi sur les campagnes électorales fédérales), les particuliers n’ont pas le droit de verser plus de 2 500 $ à chaque candidat. Comme nous le voyons dans le graphique, de nombreux dons dépassent cette limite. Deux grosses contributions versées en mai attirent notamment notre attention. Il semblerait qu’elles soient « reflétées » par des montants négatifs (des remboursements) en juin et en juillet. Une analyse plus détaillée des données révèle les transactions suivantes.
- Le 10 mai 2011, Stephen James Davis, de San Francisco, employé chez Banneker Partners (cabinet d’avocats), a donné 25 800 $ à Obama.
- Le 25 mai 2011, Cynthia Murphy, de Little Rock, employée du Murphy Group (relations publiques), a donné 33 300 $ à Obama.
- Le 15 juin 2011, un montant de 30 800 $ a été remboursé à Cynthia Murphy, réduisant le montant donné à 2 500 $.
- Le 8 juillet 2011, un montant de 25 800 $ a été remboursé à Stephen James Davis, réduisant le montant donné à 0 $.
En quoi ces chiffres sont-ils intéressants ? Les 30 800 $ remboursés à Cynthia Murphy correspondent au montant maximal qu’un particulier a le droit de donner chaque année aux comités politiques nationaux. Elle voulait peut-être simplement combiner les deux dons en une seule transaction, ce qui lui a été refusé. Les 25 800 $ remboursés à Stephen James Davis correspondent vraisemblablement aux 30 800 $ moins 5 000 $ (la limite de don à tout autre comité politique).
Dans le dernier graphique, on remarque une concentration des valeurs pour les contributions aux candidats républicains, à 5 000 $ et -2 500 $. Pour les détailler, j’ai visualisé uniquement les dons républicains. Le graphique résultant est un excellent exemple de tendances qui resteraient invisibles sans visualisation des données.
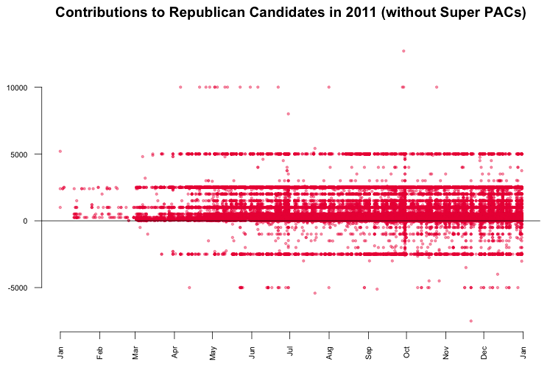
On peut remarquer qu’il y a de nombreux dons de 5 000 $ versés aux candidats républicains. En fait, si l’on regarde les données, on s’aperçoit qu’il s’agit de 1 243 dons, ce qui ne représente que 0,3 % du nombre total de dons, mais comme ces dons sont répartis uniformément dans le temps, la ligne apparaît clairement. Ce qui est intéressant dans cette ligne, c’est que comme les dons des particuliers étaient limités à 2 500 $, chaque dollar versé au-delà de cette limite a été remboursé aux donataires, ce qui produit une deuxième concentration des valeurs à -2 500 $. En comparaison, les dons versés à Barack Obama ne présentent pas un motif similaire.
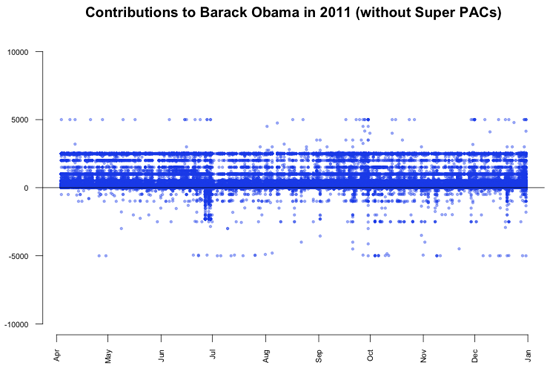
Il peut donc être intéressant d’essayer de comprendre pourquoi des milliers de donataires républicains n’étaient pas au courant de la limite de don. Pour détailler ce sujet, nous pouvons regarder le nombre total de dons de 5 000 $ par candidat.
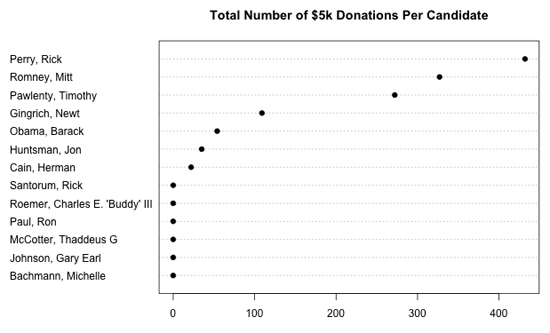
Évidemment, on obtient une vision déformée qui ne prend pas en compte le montant total des dons reçus par chaque candidat. Le graphique suivant présente le pourcentage de dons de 5 000 $ pour chaque candidat.
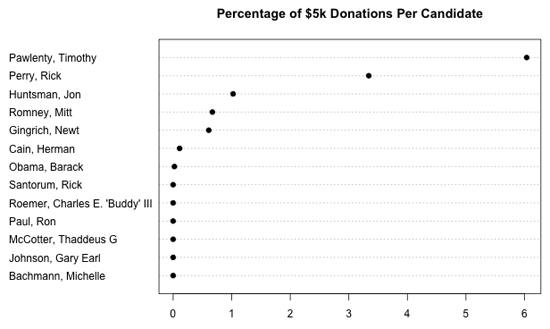
Ce qu’il faut retenir
Parfois, l’analyse visuelle d’une nouvelle base de données peut prendre des airs de voyage en terre inconnue. Vous partez en complet étranger avec simplement les données et vos hypothèses, mais à chaque pas que vous faites, avec chaque graphique que vous créez, vous obtenez de nouveaux indices. En fonction de ces informations, vous décidez des étapes suivantes et des problèmes qui valent le coup d’être étudiés. Comme vous l’aurez remarqué dans ce chapitre, ce processus de visualisation, d’analyse et de transformation des données peut être répété pratiquement à l’infini.
Le code source
Tous les graphiques présentés dans ce chapitre ont été créés à l’aide de R. Ce puissant logiciel étant conçu principalement comme un outil de visualisation scientifique, vous aurez du mal à trouver une technique de visualisation ou de transformation de données qui n’y soit pas déjà intégrée. Pour ceux que ça intéresse, voici le code source des graphiques générés dans ce chapitre :
- dons par candidat(graphique à points) ;
- tous les dons au fil du temps ;
- dons des comités autorisés.
Il existe également de nombreux livres et tutoriels sur le sujet.
Gregor Aisch, Open Knowledge Foundation