Dans les coulisses du Guardian Datablog
Quand nous avons lancé le Datablog, nous n’avions aucune idée de qui serait intéressé par des données brutes, des statistiques et des visualisations. Comme l’a formulé un ancien de la rédaction : « Qui pourrait bien vouloir de ça ? »
Le Guardian Datablog, dont je suis le rédacteur, devait être un petit blog offrant les bases de données complètes à la source de nos articles. Il comprend maintenant une page d’accueil, des outils de recherche pour explorer des données sur la gouvernance et le développement dans le monde, des visualisations de données réalisées par des graphistes du Guardian ou provenant du Web, ainsi que des outils pour parcourir des données sur les dépenses publiques. Chaque jour, nous partageons toutes nos données sur des feuilles de calcul Google ; nous visualisons et analysons ces données, puis nous les utilisons pour fournir des histoires au journal papier et au site web.
En tant que rédacteur de presse et journaliste travaillant avec des graphiques, c’était la suite logique de ce que je faisais déjà, à savoir accumuler et analyser de nouvelles banques de données pour interpréter les nouvelles de la journée.
La question qu’on se posait a trouvé sa réponse toute seule. Nous avons connu des années spectaculaires en matière de données publiques. Le premier acte législatif d’Obama a été d’ouvrir les bases de données du gouvernement américain, et son exemple a rapidement été suivi par d’autres pays : l’Australie, la Nouvelle-Zélande, ainsi que le Royaume-Uni avec le site Data.gov.uk.
Nous avons eu le scandale des notes de frais des députés, le scoop de datajournalisme le plus inattendu de Grande-Bretagne – qui oblige désormais Westminster à publier d’énormes quantités de données chaque année.
Nous avons eu des élections législatives où tous les principaux partis politiques étaient tenus à une transparence complète et ont dû ouvrir leurs bases de données au monde entier. Nous avons vu des journaux papier consacrer de précieuses colonnes à la publication de la base de données COINS du Trésor public.
Dans le même temps, alors que le Web produit de plus en plus de données, les lecteurs du monde entier sont plus intéressés par les faits bruts qu’ils ne l’ont jamais été. Quand nous avons lancé le Datablog, nous pensions attirer un public de développeurs concevant des applications. En fait, il s’agit de gens qui veulent en savoir plus sur les émissions de carbone, sur l’immigration d’Europe de l’Est, le décompte des morts en Afghanistan, ou même le nombre de fois où le mot « love » apparaît dans les chansons des Beatles (613). Petit à petit, le travail du Datablog s’est mis à refléter et à enrichir les histoires que nous rencontrions. Nous avons crowdsourcé 458 000 documents sur les dépenses des députés britanniques et nous avons analysé les données détaillées des demandes de remboursement de chaque député. Nous avons aidé nos utilisateurs à explorer les bases de données détaillées des dépenses du Trésor et nous avons publié toutes les données à la source de nos informations.
Mais au printemps 2010 s’est produit un évènement qui a changé la donne, avec la publication d’une feuille de calcul : 92 201 lignes de données, chacune contenant les détails d’un évènement militaire en Afghanistan. Il s’agissait des journaux de guerre de WikiLeaks. Ou plutôt, de la première partie. Deux autres épisodes allaient suivre : l’Irak et les télégrammes diplomatiques. Le terme officiel pour les deux premières parties était SIGACTS, pour Significant Actions Database (base de données des actions importantes de l’armée américaine).
Dans les organisations de presse, tout est question de géographie – et de proximité de la rédaction. Si vous êtes proche, il est facile de suggérer des histoires et de faire partie du processus ; à l’inverse, loin des yeux, loin du cœur. Avant WikiLeaks, nous étions placés à un étage différent, avec les graphistes. Depuis WikiLeaks, nous partageons le même espace que la rédaction. Il nous est donc plus facile de suggérer des idées à la rédaction, et pour les reporters de penser à nous quand ils ont besoin d’aide.
Il n’y a pas si longtemps encore, les journalistes étaient les gardiens des données officielles. Nous écrivions des histoires à partir des chiffres qui nous parvenaient et nous les révélions au public reconnaissant, qui ne s’intéressait pas aux statistiques brutes. L’idée de divulguer des informations brutes dans nos journaux était une abomination.
Cette dynamique a été complètement bouleversée. Nous sommes devenus des interprètes ; nous aidons les gens à comprendre les données, et nous les publions simplement parce qu’elles sont intéressantes en elles-mêmes.
Mais des chiffres sans analyse ne restent que des chiffres, et c’est là que nous entrons en jeu. Quand le Premier ministre britannique a déclaré que les émeutes d’août 2011 n’étaient pas liées à la pauvreté, nous avons établi une carte corrélant les adresses des émeutiers avec des indices de pauvreté pour déterminer le degré de vérité de cette affirmation.
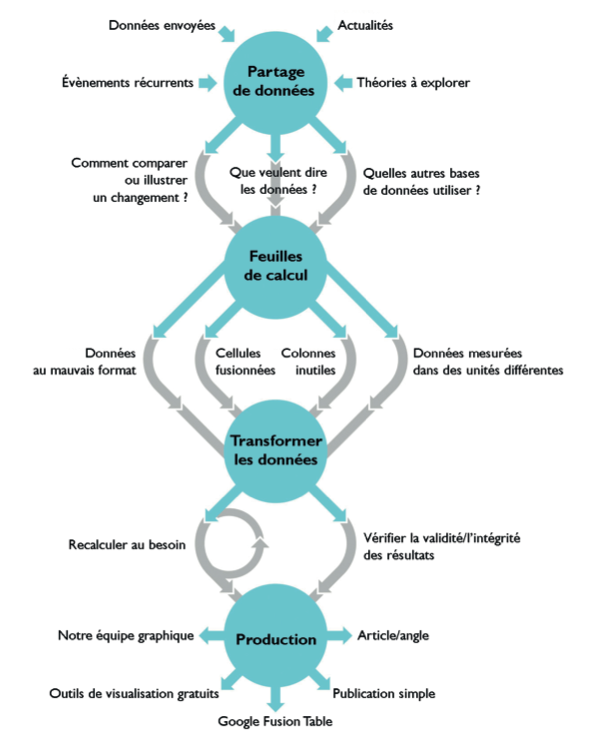
Derrière toutes nos histoires de datajournalisme, il y a un processus. Il évolue en permanence car nous ne cessons d’utiliser de nouveaux outils et de nouvelles techniques. Certaines personnes pensent qu’il faut devenir une sorte de super hacker, écrire du code et manger du SQL au petit-déjeuner. Vous pouvez décider de suivre cette approche. Mais une grande partie de notre travail se fait simplement dans Excel.
Tout d’abord, nous localisons les données ou nous les obtenons auprès de diverses sources, que ce soit des dépêches, des données gouvernementales, des études journalistiques, etc. Puis, nous commençons à étudier ce qu’il est possible de faire avec ces données ; devonsnous les recouper avec une autre base de données ? Comment pouvons-nous illustrer leur évolution au fil du temps ? Ces feuilles de calcul doivent bien souvent être sérieusement nettoyées – toutes ces colonnes superflues et ces cellules bizarrement fusionnées ne sont pas d’une grande aide. Et c’est à supposer que ce ne soit pas un PDF, le pire format de l’humanité pour les données.
Souvent, les données officielles sont accompagnées de codes officiels ; chaque école, hôpital, circonscription et autorité locale possède un identifiant unique. Chaque pays en possède également un (le code de la France est FR, par exemple). Ces identifiants peuvent être utiles si vous commencez à mélanger plusieurs bases de données, car il existe un nombre incroyable de variations alphabétiques. Il y a la Birmanie et le Myanmar par exemple, ou bien le comté de Fayette aux États-Unis (il y en a 11). Les codes permettent de comparer ce qui est comparable.
Au bout de ce processus, il y a le produit : sera-ce une histoire, un graphique ou une visualisation, et quels outils allons-nous utiliser ? Nous employons principalement des outils gratuits qui nous permettent de produire quelque chose rapidement. Les graphiques plus sophistiqués sont produits par notre équipe de développement. Ainsi, nous utilisons couramment des Google Charts pour les graphiques les plus simples, ou Google Fusion Tables pour créer des cartes en toute facilité.
On pourrait croire que c’est novateur, mais ça ne l’est vraiment pas. Dans la toute première édition du Manchester Guardian (le samedi 5 mai 1821), les nouvelles étaient au verso, comme dans tous les journaux de l’époque. Le premier élément sur la couverture était un avis de recherche pour un labrador égaré. Au milieu des histoires et des extraits de poésie, un tiers de la quatrième de couverture était occupé par des faits : un tableau complet des frais de scolarité dans la région « encore jamais dévoilé au public », écrit « NH ».
NH voulait que ses données soient publiées pour ne pas les laisser rapporter par des gens d’église incompétents en la matière. Il exprimait sa motivation en ces termes : « De telles informations sont précieuses, car sans savoir dans quelle mesure l’éducation … prévaut, les meilleures opinions pouvant être formées sur la condition et le progrès futur de la société seront nécessairement incorrectes. » En d’autres termes, si les gens ne savent pas ce qui se passe autour d’eux, comment la société pourrait-elle s’améliorer ?
Je ne peux pas trouver de meilleure raison à faire ce que nous essayons de faire. Des informations qui étaient autrefois rapportées en quatrième de couverture peuvent aujourd’hui paraître à la une.
Simon Rogers, The Guardian