La couverture des émeutes au Royaume-Uni par le Guardian Datablog
Au cours de l’été 2011, l’Angleterre a été touchée par une vague d’émeutes. À l’époque, des politiciens avaient prétendu que ces actions n’avaient aucun lien avec le taux de pauvreté et que les pilleurs étaient de vulgaires criminels. De plus, le Premier ministre et les principaux politiciens conservateurs avaient accusé les réseaux sociaux d’avoir provoqué les émeutes, suggérant que ces plates-formes avaient attisé la violence et que les émeutiers s’étaient organisés par Facebook, Twitter et Blackberry Messenger (BBM). Certains ont appelé à bloquer temporairement l’accès aux réseaux sociaux. Comme le gouvernement n’a pas ouvert d’enquête sur les raisons des émeutes, The Guardian, en collaboration avec la London School of Economics, a réalisé un projet révolutionnaire intitulé « Reading the Riots » (« Lire les émeutes ») pour répondre à ces questions.
Le journal a ainsi fait la part belle au datajournalisme pour permettre au public de mieux comprendre qui avait participé aux émeutes et pourquoi. Par ailleurs, le journal a collaboré avec une autre équipe d’universitaires, dirigée par le professeur Rob Procter de l’université de Manchester, pour mieux comprendre le rôle des réseaux sociaux, que The Guardian lui-même avait largement utilisés pour couvrir les émeutes. L’équipe de Reading the Riots était dirigée par Paul Lewis, le rédacteur des projets spéciaux du Guardian.
Au cours des émeutes, Paul avait rapporté des nouvelles du front dans plusieurs villes d’Angleterre (notamment par le biais de son compte Twitter, @paullewis). Cette seconde équipe a travaillé sur 2,6 millions de tweets concernant les émeutes, fournis par Twitter. Le principal objet de ce travail sur les réseaux sociaux était de comprendre comment les rumeurs circulaient sur Twitter, quelle fonction jouaient les différents utilisateurs/acteurs dans la propagation des informations, dans quelle mesure la plate-forme avait été utilisée pour inciter à la violence, et d’observer de nouvelles formes d’organisation.
En matière de datajournalisme et de visualisation de données, il est utile de distinguer deux périodes-clés : la période des émeutes à proprement parler et la façon dont les données ont permis de raconter leur déroulement en temps réel ; puis une période d’étude plus intense avec deux équipes universitaires collaborant avec The Guardian pour recueillir des données, les analyser et produire des rapports détaillés. Les résultats de la première phase du projet Reading the Riots ont été publiés au cours d’une semaine de couverture intense au début du mois de décembre 2011. Ci-après figurent quelques exemples-clés de l’utilisation du datajournalisme au cours de ces deux périodes.
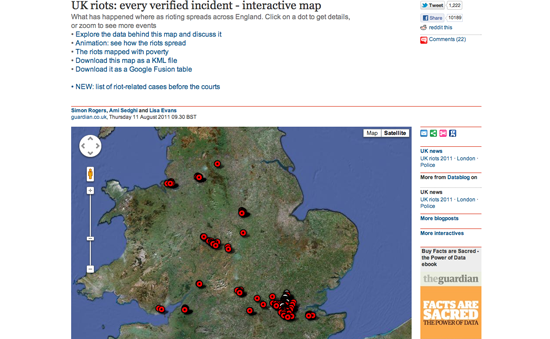
Phase un : les émeutes en temps réel
Avec des cartes simples, l’équipe de datajournalisme du Guardian a cartographié l’emplacement des émeutes confirmées, puis en recoupant des données sur le taux de pauvreté avec la localisation des émeutes, elle a commencé à déconstruire le mythe politique qui voulait que les émeutes n’aient aucun lien avec la pauvreté. Ces deux exemples utilisent des outils de cartographie prêts à l’emploi, et le second combine des données géographiques avec une autre base de données afin d’établir des recoupements.
Concernant l’utilisation des réseaux sociaux (en l’occurrence, Twitter) au cours des émeutes, le journal a créé une visualisation des hashtags liés aux émeutes publiés au cours de cette période, qui soulignait que Twitter avait principalement été utilisé pour répondre aux émeutes plutôt que pour planifier des pillages, le hashtag #riotcleanup (une campagne spontanée visant à nettoyer les rues après les émeutes) présentant le plus fort pic de trafic au cours de cette période.
Phase deux : décrypter les émeutes
Quand le journal a rapporté les résultats de plusieurs mois d’enquête intensive et de collaboration étroite avec deux équipes universitaires, deux visualisations sont ressorties du lot et ont beaucoup fait parler d’elles. La première est une courte vidéo présentant le recoupement des endroits où des émeutes se sont produites avec les adresses des émeutiers, ainsi qu’une sorte d’itinéraire des émeutes. Pour ce faire, le journal a travaillé avec un spécialiste de la cartographie des transports, ITO World, afin de modéliser l’itinéraire le plus vraisemblablement emprunté par les émeutiers pour aller commettre leurs pillages, établissant des parcours différents selon les villes, avec parfois de longues distances parcourues.
La seconde visualisation s’intéresse à la propagation des rumeurs sur Twitter. En accord avec l’équipe universitaire, sept rumeurs ont été sélectionnées pour analyse. L’équipe universitaire a ensuite recueilli toutes les données liées à chaque rumeur et a conçu un système de codage pour classer les tweets selon quatre critères : les gens qui répétaient simplement la rumeur (affirmation), qui la réfutaient (négation), qui la remettaient en question (question) ou qui la commentaient (commentaire). Toutes les tweets ont été codés en trois exemplaires et les résultats ont été analysés par l’équipe interactive du Guardian. L’équipe du Guardian a détaillé le développement de cette visualisation sur son site.
Ce qui est si frappant dans cette visualisation, c’est qu’elle montre de façon percutante quelque chose de très difficile à décrire, à savoir la nature virale des rumeurs et leur cycle de vie. Le rôle des médias dominants est manifeste dans certaines de ces rumeurs (par exemple en les réfutant ou en les confirmant rapidement), de même que la nature corrective de Twitter lui-même. Non seulement cette visualisation permettait d’enrichir le storytelling, mais elle donnait une bonne idée de la façon dont les rumeurs circulaient sur Twitter, apportant des informations utiles pour gérer de futurs évènements.
Ce qui apparaît clairement dans ce dernier exemple, c’est la puissante synergie entre le journal et l’équipe universitaire qui a permis d’analyser 2,6 millions de tweets de manière détaillée. Bien que l’équipe universitaire ait développé des outils sur mesure pour cette analyse, elle travaille maintenant à les rendre plus largement accessibles à quiconque souhaiterait les utiliser pour ses propres analyses. Combinés au mode d’emploi fourni par The Guardian, ces outils constitueront une étude de cas utile démontrant comment de telles analyses et visualisations des réseaux sociaux peuvent être utilisées pour raconter des histoires.
Farida Vis, université de Leicester